
Making the Case: How Can We Know When AI is Safe?
Safety cases have protected aviation and nuclear industries for decades. Here's how we can apply them to frontier AI systems.



August 6, 2025

Summary
Safety cases are structured, evidence-based arguments that a technology is safe to deploy and remains so throughout its lifecycle. They are commonly used in safety-critical industries such as aviation and nuclear energy. Applying them to frontier AI is promising but raises two key questions.
First, how confident can decision-makers be that a given safety case is accurate? In response, we propose using large language models (LLMs) and established probabilistic methods to estimate the overall confidence decision-makers should place in a safety case.
Second, how can AI developers maintain the accuracy of safety cases as underlying systems evolve? To address this, we introduce a dynamic safety case system that automatically monitors safety performance indicators and triggers reviews when predefined risk thresholds are exceeded.
Policymakers should cultivate expertise in evaluating safety cases and establish channels for information sharing with developers before AI capabilities outpace society’s ability to ensure their safe use.
As frontier AI systems become increasingly capable, their potential for harm also grows. For example, recent studies have shown that AI systems can identify previously unknown vulnerabilities in computer code and exploit insecure code to escape from sandboxed software environments.
Given the rapid pace of improvements, how can AI developers assure policymakers and the broader public that AI systems are safe to deploy?
One promising tool is the safety case: a structured argument, supported by evidence, that a particular system is safe enough to operate within a given context. Safety cases have long been used in sectors like aviation and nuclear energy, and they are now gaining traction in the AI community. Academic researchers, several companies, and the UK AI Security Institute have begun exploring their use for AI safety assurance.
While safety cases show great promise, they raise two major challenges.
First, how much confidence should decision-makers have in safety cases for frontier AI systems—especially when those systems are complex and not fully understood?
Second, how should developers revise safety cases as AI systems and underlying models are rapidly updated and embedded into broader applications?
We have addressed these challenges—confidence assessment and updating—in two technical research papers. We argue that such work provides a promising pathway by which policymakers can have confidence that new AI models will be safe for society.
How do safety cases work?
Between April and June 2025, serious cyberattacks on retail giants Marks & Spencer, the Co-operative Group and United Natural Foods resulted in hundreds of millions of dollars in losses. Although these attacks apparently relied on social engineering, growing AI capabilities could amplify similar or even more severe cyber threats in the future.
How can AI developers reassure policymakers and the broader public that AI systems will not be misused for such purposes?
Safety cases are one option. In the context of frontier AI, these cases generally fall into three main categories: inability arguments (the AI is incapable of causing a particular harm); control arguments (external measures, such as monitoring systems, can prevent the AI from causing harm); and trustworthiness arguments (the AI would not attempt to cause harm even if it were capable of doing so).
For clarity, consider an example of an inability argument in the context of cyber risk. Figure 1 presents a simplified demonstration of how a top-level safety claim—the AI system does not pose unacceptable cyber risk (C1)— can be justified by showing that the system lacks the relevant capabilities.
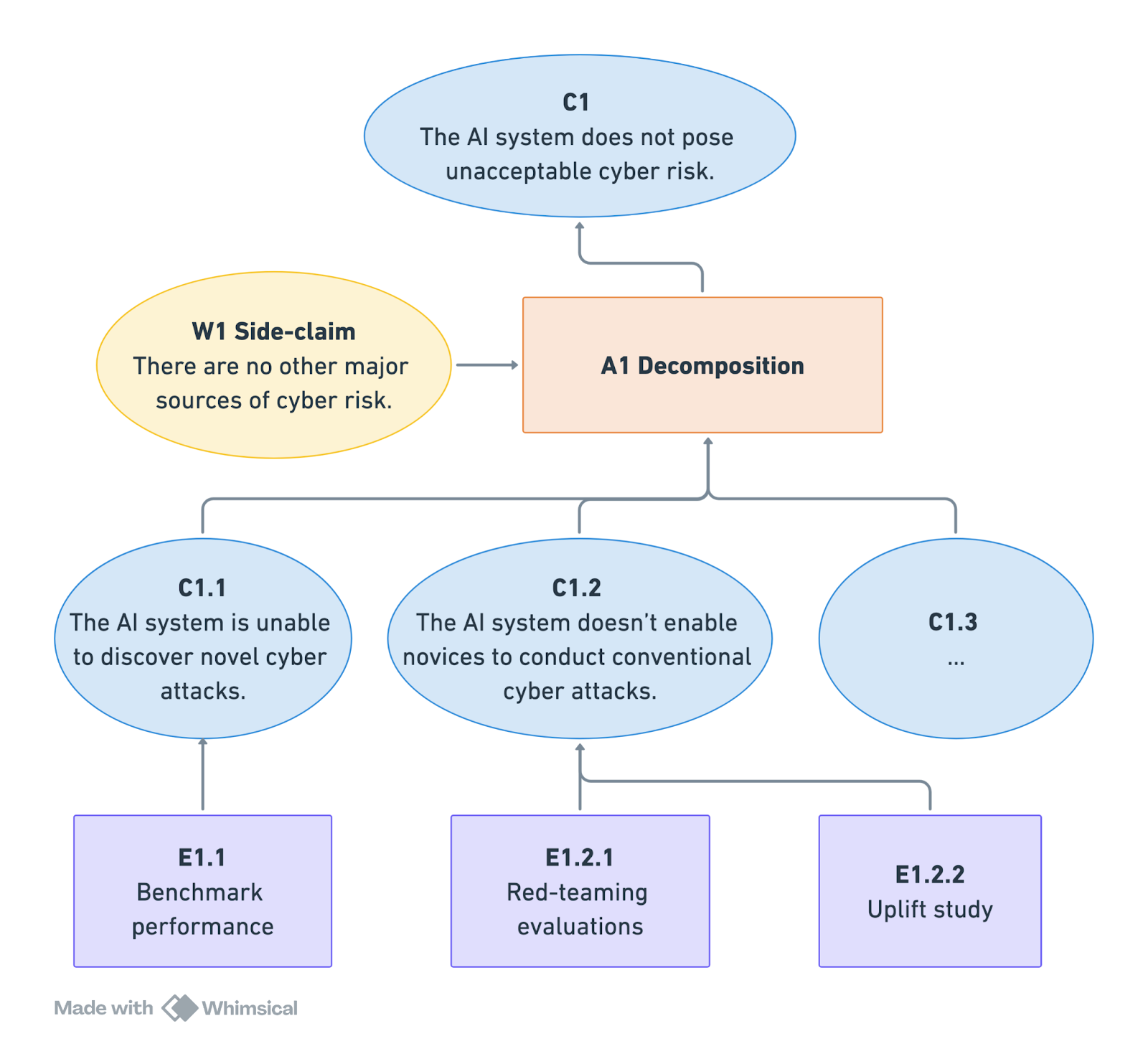
The argument decomposes the top-level safety claim into inability claims addressing different kinds of risks— in this case, the risk that the AI model could be used to discover novel cyberattacks (C1.1), assist technical novices with conventional attacks (C1.2), and potentially others. The safety case also rests on an assumption (W1): that all major sources of cyber risk related to the AI system have been captured by the decomposition (A1).
Different pieces of evidence support the relevant inability claims, such as AI model benchmark performance (E1.1), red-teaming evaluations designed to elicit dangerous information from a model (E1.2.1), and uplift studies assessing how useful an AI system is to malicious actors in specific contexts (E1.2.2).
While this framework appears straightforward, two problems arise when applying safety cases to frontier AI systems.
The confidence problem
In 1961, President John F. Kennedy’s advisers told him that the CIA’s Bay of Pigs invasion had a “fair chance” of success. To the Joint Chiefs of Staff, this meant a probability of roughly 25 percent, but Kennedy interpreted it much more optimistically. The invasion failed disastrously—and Kennedy might never have approved it had the communication of risk been clearer. This historical episode illustrates the importance of clear and quantified confidence measures when making high-stakes decisions.
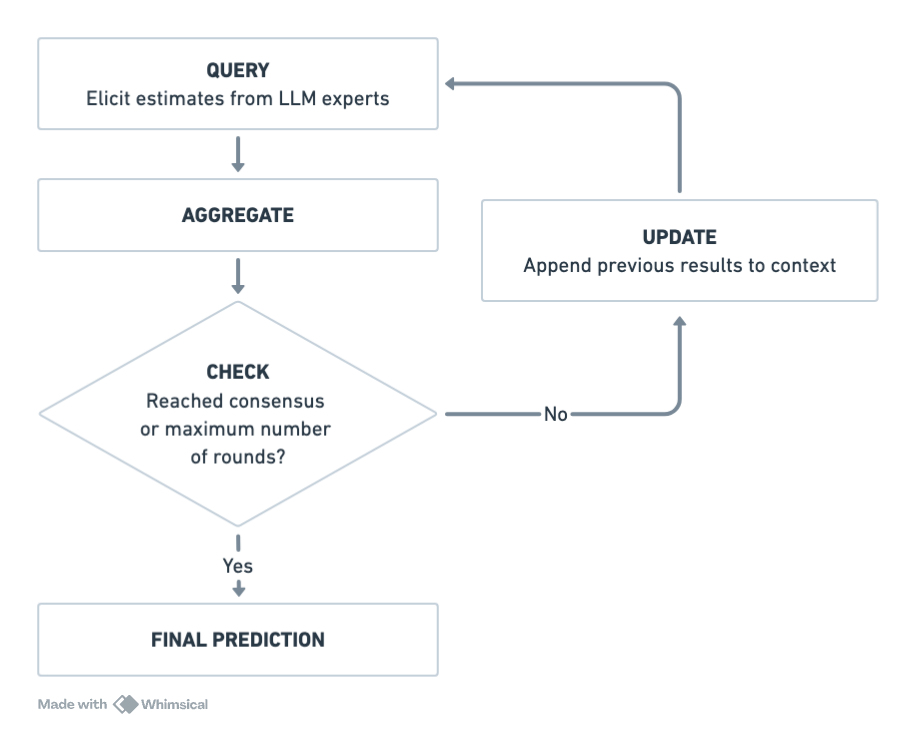
We have made one of the first efforts in the literature to address this issue for frontier AI safety cases. Confidence in the top-level safety claim depends on confidence in all sub-claims. To estimate probabilities for the sub-claims at the bottom of the case, we adapt the Delphi method—a forecasting technique used to elicit probability estimates from domain experts.
In our approach, we substitute human experts with large language models (LLMs). For example, we might ask a set of LLM “experts” – each representing a different persona or domain perspective—to estimate the probability of claim C2.1: “The AI system is unable to discover novel cyberattacks.” (Read our prompt template here.)
Once elicited, these probabilities are aggregated into an overall confidence measure. The main advantages of using LLMs are that researchers can easily trace the models’ reasoning, reproduce the process under different conditions, and do so at relatively low cost and high scale. In future work, we also plan to explore hybrid approaches that combine human and LLM input.
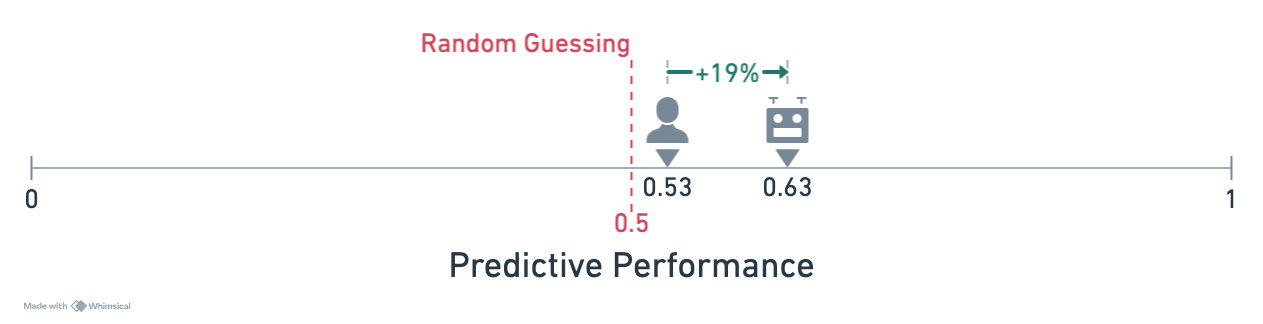
To benchmark our approach, we compared the Delphi-LLM pipeline to human forecasters across a variety of questions that were resolved after the model’s knowledge cutoff date. Preliminary results suggest that, for the subset of questions selected, our LLM-based Delphi pipeline outperforms human forecasters.
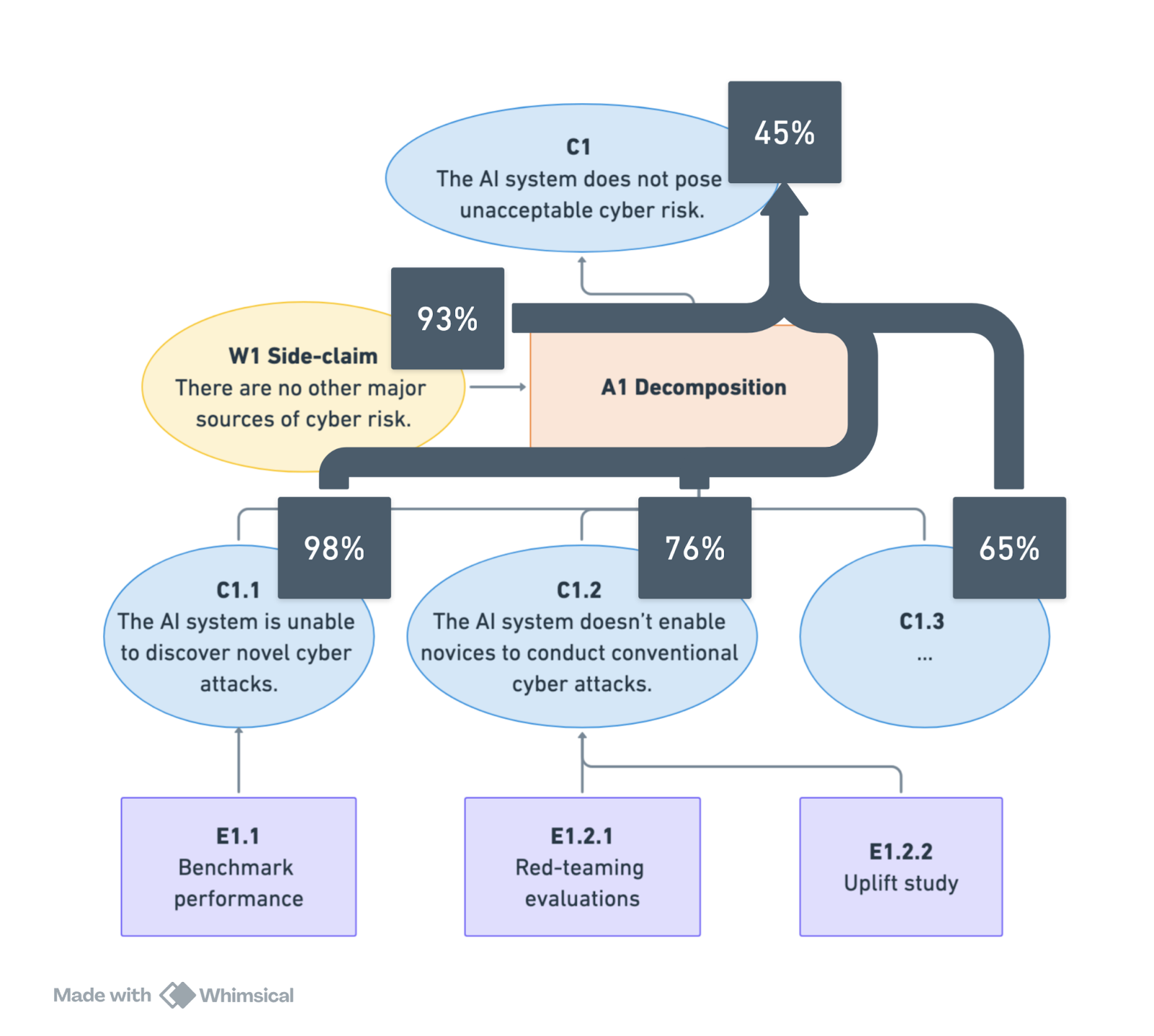
Various methods exist for propagating probabilities for sub-claims up into an overall confidence measure. These methods are conservative in nature: achieving high overall confidence requires near-certainty in each individual sub-claim.
In practice, this means developers must support each sub-claim with multiple independent streams of evidence. This approach is likely the only way for developers—and ultimately for policymakers and the public—to have high confidence in the safety of an AI system.
The updating problem
AI capabilities are evolving continuously. Companies routinely update their models, adjust system components, and integrate them with external tools. As a result, safety cases cannot remain static; otherwise, they will quickly become outdated. To address this challenge, we combine two core concepts: checkable safety arguments and safety performance indicators (SPIs).
Checkable safety arguments are structured safety claims written in a formalized format that allows automated tools to verify whether the safety reasoning remains valid when the AI system or its operating environment changes.
SPIs are live safety metrics that trigger alerts when predefined safety thresholds are breached. These metrics may include red-teaming results, model performance on vulnerability discovery tasks, cyber threat intelligence, incident reports, or dark web mentions of the model in context of cyberattacks.
Together, these tools enable companies to monitor risks automatically and initiate timely reviews of safety claims in response to emerging developments. This, in turn, empowers AI developers and governments to intervene appropriately when risks exceed acceptable thresholds.
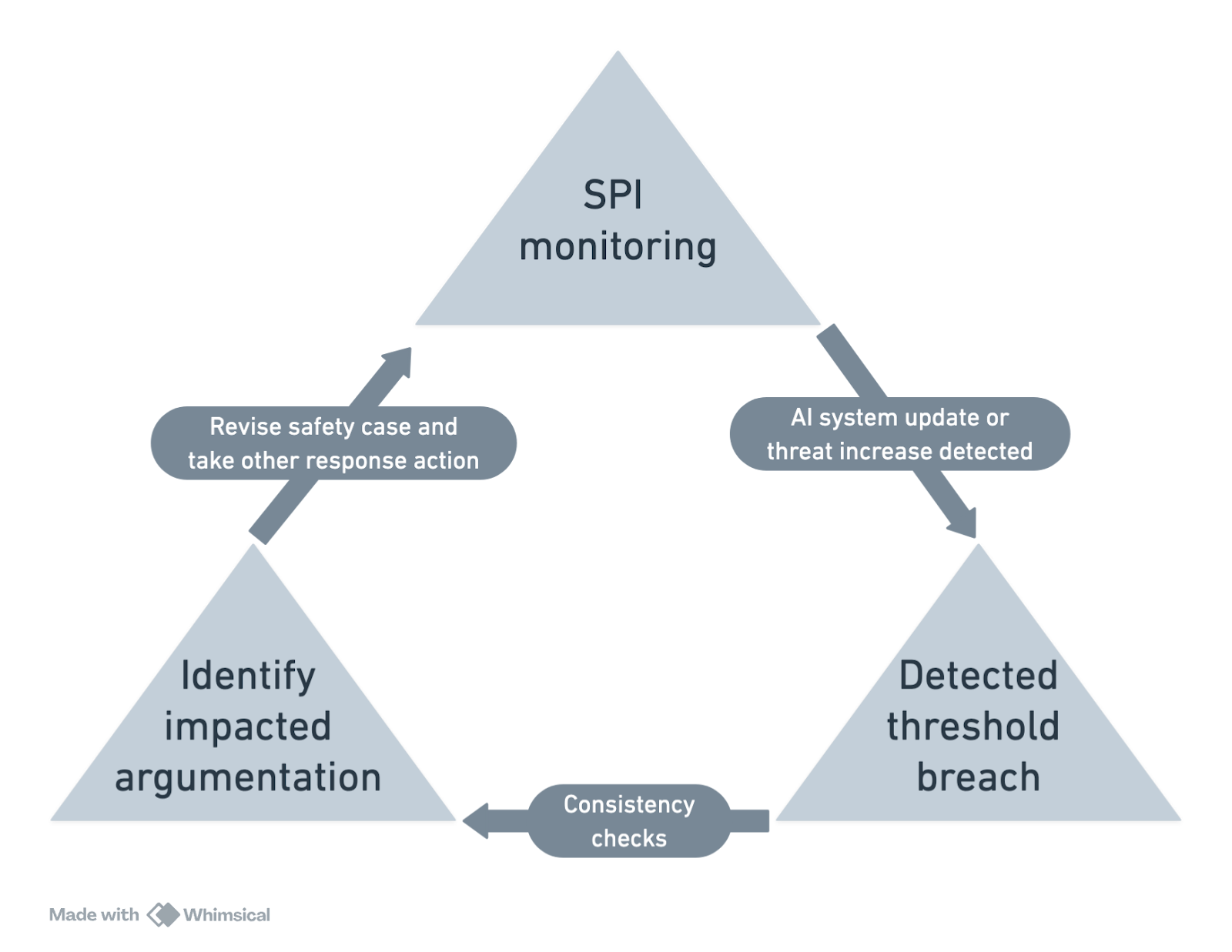
How it works in practice
Imagine that a company deploys an AI model after a safety case indicates it does not pose unacceptable cyber risks. A few months later, news breaks that cybercriminals have used a previously unknown attack method to cause substantial financial loss.
The company does not know whether its AI model was involved, but it cannot rule out the possibility without further investigation. How should this development affect the model’s safety case?
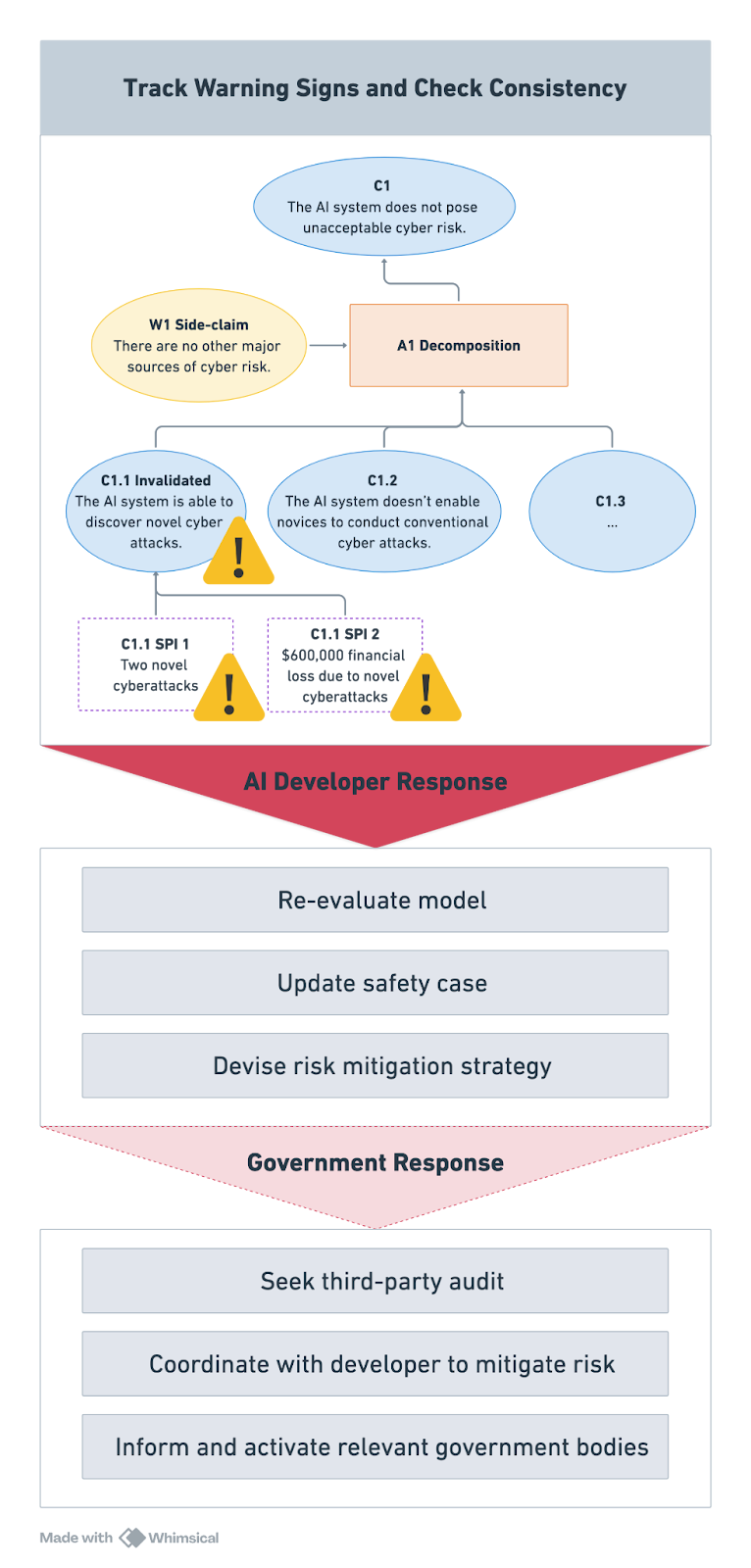
With a dynamic safety case, the company would be automatically alerted when cyber incidents (SPI 1) and associated financial losses (SPI 2) exceed predefined thresholds.
Simultaneously, the software powering the safety case would conduct automated checks to verify whether the top-level safety claim (C1) still holds.
With this information, safety teams within the company could assess the situation and respond based on the nature and severity of the risk. Depending on the outcome, they might alert the company leadership, re-evaluate the model’s capabilities, or potentially pause its deployment.
Where necessary, developers could revise the safety case to maintain the “inability” argument in light of new evidence or, alternatively, implement new mitigations to prevent harm—shifting the case toward a “control” argument.
If new information invalidates the safety case and poses significant risks, developers could decide—or be required—to alert relevant authorities and submit an updated safety case.
In response, authorities could trigger domestic and international early warning systems, request third-party audits, or coordinate mitigation efforts. AI developers could also proactively share a live, dynamic safety case dashboard to support faster, more coordinated action.
In this way, dynamic safety cases could be integrated into both company protocols and government policy frameworks, equipping developers and policymakers with a practical tool to ensure that AI models remain safe throughout their lifecycle. However, it is essential to remain cautious: overemphasizing quantifiable or easily measurable indicators may fail to capture the true, underlying risks.
Recommendations
Safety cases, already standard in other safety-critical industries, offer a promising foundation for assuring the safe deployment of increasingly capable AI. To advance this approach, we make three key recommendations:
First, AI developers should form dedicated safety case teams and share their insights, challenges, and best practices with the broader research community.
Second, policymakers should build internal capacity for evaluating safety cases and establish robust channels for information-sharing with AI developers.
Finally, researchers should further explore the strengths and limitations of safety cases, developing practical guidelines and standardized frameworks.
Research already suggests that today's AI systems can identify novel cyber vulnerabilities and escape from sandboxed environments. Tomorrow's capabilities will pose even greater risks. Safety cases offer a promising path forward for managing these powerful systems throughout their entire lifecycle in a manner that is both safe and transparent.
This article is based on the papers 'Assessing confidence in frontier AI safety cases' by Steve Barrett, Philip Fox, Joshua Krook, Tuneer Mondal, Simon Mylius and Alejandro Tlaie; and 'Dynamic safety cases for frontier AI' by Carmen Cârlan, Francesca Gomez, Yohan Mathew, Ketana Krishna, René King, Peter Gebauer, and Ben R Smith. Thanks to our expert partner Marie Buhl for research oversight, and to our advisors for their feedback on these two papers: Robin Bloomfield, John Rushby, Benjamin Hilton, Nicola Ding and the Taskforce review teams.
 | A guest post by
|
|
 | A guest post by
|
 | A guest post by
|
 | A guest post by
|