
AI Safety Can't Go On Like This

An extended version of this contribution was first published as a two-post series on Threading the Needle.

As AI policy challenges have grown far beyond the frontlines of 2023, the AI safety movement struggles to maintain its position on 2025’s political map. Can the movement marry AI safety policy to larger political causes, in hopes of riding a more mainstream wave to legislative success (e.g. potential movement opposed to AI labor market disruptions)? Can the AI safety movement wait for external shocks to make policy makers realize the gravity of their concerns (e.g. impending cases of large-scale AI misuse)? In this piece I’ll look back at how the safety movement got into its current strategic bind, and attempt to sketch a way forward.
The old model isn’t working anymore. World leaders seem to have – partly – woken up to the fact that AI is going to be a big deal; but they’re not drawing ‘safetyist’ conclusions from that insight. With the stakes becoming increasingly real, governments are becoming increasingly fierce in their pursuit of a ‘place in the sun’. They scratched the inscriptions off the eponymous safety summits, publicly condemned the very notion of safety policy, and pretty much shut the door on any notion of spinning the fleeting victories of 2023 into a lasting international consensus. I believe this is not just a temporary setback, but points to a much-needed strategic realignment.
That is a tough pill to swallow. Capability growth is rapid, realignment takes time, crunch-time is now – a bad time to face fundamental reconsiderations. And it’s not like the old safetyist playbook never worked: The first years of safety policy scored some impressive successes. It’s a natural reaction to setbacks to think that one just ought to hunker down and redouble one’s efforts. But that wouldn’t do. It’s also a natural reaction to think that the brand is now marred, and the challenge is primarily one of rebranding – say, to AI security instead. But these interpretations miss some more fundamental shifts that have hurt the safety pitch. Understanding what used to work helps finding out what to change.
The End of the 2023 Playbook
The success stories of AI safety policy have been stories of shaping people’s first encounters with AI in a way that nudges them toward safetyist conclusions. Perhaps the most notable example is Rishi Sunak, whose repeated encounters with high-profile safety advocates led to two of the most notable early successes of AI safety policy: The foundation of the UK AISI and subsequent AISIs in other jurisdictions, and the AI Safety Summit that led to commitments made at Bletchley and Seoul and a comprehensive scientific report. Lining up independent experts and having them talk to major decision makers has long been a self-evident part of the safety movement’s identity. For two reasons, I think the time for that blueprint is over, at least in the major AI jurisdictions.

No More First Impressions
First – people now know about AI, so the strategy of being the first to know what’s going on doesn’t work anymore. Early on, the safety pitch was a package deal: Policymakers would receive sound, well-presented information on an issue they urgently wanted to get up-to-speed on from the world’s leading experts. These experts could then couch their expertise in cautionary tales of the risks of AI, and how easy it is to fall off the glorious path. That worked well, because qualified explanations of AI were in short supply and high demand, and experts had creative leeway to impress upon policymakers the gravity of the situation.
It works less well now; both because policymakers genuinely do know more, but also because they think they know more about AI than they do. I think it’s fair to argue that many politicians still don’t really get what’s coming. But in 2023, politicians were conscious of their ignorance – they were happy to admit they didn’t know much about AI and needed external input. This is less true now: there’s less demand for noncontroversial expert opinions on what this new technology is about.
Political advice one can reasonably give to decision makers on AI is now closer to other kinds of political advocacy. Experts are often seen as pundits, and the safety movement now requires alliances and political capital. That’s a much worse position for expert-driven advocacy to be in – anyone who has worked in lobbying or advocacy knows what I mean: It’s much more frustrating to brief a politician on an issue they mistakenly consider themselves an expert on.
No More Neutral Experts
Second – policymakers are already primed on the mainstays of AI policy debate. 2023’s safety advocates framed their concerns with a blank piece of paper: If you had to convince a conservative, you’d frame your case around national security, if you had to convince a liberal, you’d frame your case around reigning in big tech. The situation is different today. AI safety already has a reputation as a Biden-era instance of tech regulation – good framing only gets you so far once that’s the case. Again, this is a commonplace experience in policy advocacy: the policymaker’s adversarial reflex of ‘wait, but isn’t this exactly what the other guys wanted last year’ reliably beats out clever and meritorious reframing.

Both high-profile experts, and the policies they advocate for have acquired reputations and affiliations. Finding out on which side of the highly-politicized SB-1047 debate someone was is just one google search away, and enough information to discredit many AI safety advocates. Policymakers not privy to the debate so far will be quick to ask their aides for basic rundowns of safety advocates, and the briefings they get will often not be deemed ‘decidedly neutral information’.
In many ways, the safety movement finds itself in the often-evoked story of the team in the locker room, down 7-21 at half-time in the superbowl – just realising that the strategy that got them there won’t get them across the finish line. They’re closer to winning than most will ever get. But to do it, they’ll have to pivot, fast.
Safety Policy Lacks Political Leverage
So what’s keeping the safety movement from scoring? External reasons are part of the answer. The vibe swung against Democrats and against tech regulation, and safety policy was associated with both. Now that a lot of information is out there and the issue is sufficiently salient, current AI policymaking is about motivating policymakers to prioritize your view of the issue. I believe that safety policy currently does not pull enough levers that affect politicians’ priorities.
No Enduring Public Support
The first lever is vocal public support. The standard response to this is that AI safety polls well – if you ask people whether they support safety-focused regulation, they tend to say yes. But that’s not enough – if you ask people to prioritize the issues they care about, AI safety is nowhere to be seen. And neither is any greater issue that can be reasonably construed to be related to AI safety; not even terrorism or disempowerment score particularly highly. Counter-positions to AI safety, on the other hand, can leverage popular support by association with salient issue clusters: Acceleration as a boost to the economy, deregulation as slashing bureaucracy, racing as cementing American supremacy. Despite nominal approval for safety measures, safety policy is no vote winner yet.
The AI safety movement has ended up downstream from a strategic design decision of positioning itself as an elite movement – with little reach or pitch to the general public. A few notable exceptions to that ‘elite’ strategy have either backfired, or are conducted by fringe actors that seem to reject coherent message discipline. This would not be an easy pivot; the very structure of the movement – the style of messaging, the strengths of leadership and the content of the arguments – is very difficult to translate into an initiative with broader public appeal
No Partisan Platform
One way to avoid having to rally this kind of grassroots support is the second lever: Strong platform affiliation. If a position is woven into the political platform of a major political party, it’ll have its day in the sun eventually: Majorities shift, and that means eventual progress on the issue. Unless an area is extraordinarily politicized, it’ll be very difficult to completely roll back all achievements. But even though the safety platform has suffered from backlash against Democrat policies, it hasn’t found solid purchase in the Democrat platform. No notable Democrat campaigned on their achievements in AI regulation, nor does the Democratic party seem particularly shocked about the Trump administration’s turn away from safety.
There have been few Democrat responses to Vice President Vance’s Paris remarks, disavowing safety as the headline term for the AI summit. Neither did the Democrats attempt to protect the AISI and associated executive orders. In my eyes, there’s little hope that Democrats will make AI safety a priority in 2026 or 2028. It certainly hasn’t been a mainstay of their post-inauguration messaging thus far. Even former FTC Chair Lina Khan’s post-exit interviews have generally not addressed the AI topic from a safetyist point of view. Safety policy finds itself in the worst of both worlds: It’s Dem-coded enough to suffer political retaliation, but not Dem-coded enough to be enacted on the coattails of general Democratic victories.
No Majority in Secret Congress
A third alternative lever: If you can pitch a slightly adjusted framing of your policy agenda that appeals to both political sides, you don’t need to get deep into politics for the agenda to succeed. You can fly under the radar and get your pitch through Secret Congress. However, to achieve bilateral appeal on technocratic merit you need your policy of choice to be cheap. If your policy is costly, there is ample incentive for one side to drag it out of Secret Congress, frame it as partisan, and score quick political points.
Many AI safety policy demands are not cheap. Consolidated alignment research, misgivings about loss of potential economic growth from slowing down development (though of course, preventing disaster and extinction would be a net positive) can be construed as not just expensive, but detrimental to American hegemony. AI safety policy is often seen as politically costly. No policymaker wants to be complicit in losing the race to China. AI safety policy comes at a steep political price, because it’s perceived as incompatible with the domestic deregulation agenda. AI safety is seen as geopolitically risky and Democrat-coded in times of a massively unpopular Democratic party.
The Political Economy Might Not Fix Itself
This political economy does not serve the safety platform. It might get better by itself, but that’s not guaranteed. Many (contentious) political causes have benefited from their focused risks manifesting: Natural disasters strengthen the case for environmental causes; foreign terrorism tends to catalyze migration crackdowns. After Three Mile Island, political support for nuclear power dropped dramatically. The political economy of prosaic risks tends to self regulate when faced with escalating consequences that force action. This is not necessarily true for AI, which could go well up until it goes really badly.
Instances of large-scale AI misuse, systematic failure, or loss of control can shift the political economy back. But a disaster ‘wake-up call’ is far from guaranteed. It might just be that the first instance of an AI safety accident has not disastrous, but catastrophic consequences. Any broader wake-up call on AI writ large is not guaranteed to help the safety movement: If 2027 saw a big AI scare due to deepfakes or job disruptions, it seems far from certain that the political response to that would be particularly conducive to safety specifically. In effect, we might well have to zero-shot learn about the importance of safety. How could that work?
What Could Be Done?
Diversify the Pitch
My overall suggestion is to better position the safety movement to take advantage of emerging political opportunities. Through the fog of war, it seems highly uncertain whether the winning safety play will come from a grassroots burst of public support, on the back of a strong partisan affiliation, or through technocratic consensus. As long as that’s unclear, it seems most promising to hedge one’s bets and prepare to make a winning safety case on all levels. But for that to work, I believe, you’ll need a slightly different movement: One that is heterogeneous enough so that not nearly every safety advocate gets lumped in with every other safety advocate and exposes them to political risk. Otherwise, attempts to focus public attention on the issue of safety will hurt your technocratic credibility. Conversely, technocratic neutrality hurts your partisan framings, and one partisan pitch discredits the other. Only a safety movement perceived as less monolithic and monocultural would be able to play this field well.
I go into much greater detail on this proposal and the reasoning behind it in a recent post. In essence, I think the best way to strengthen that strategic position is the following:
Diversify organisational focus – Mono-strategy organisations that chiefly focus on policy research and refrain from advocacy need to focus on expert consensus, and refrain from contentious suggestions. They need to pursue public advocacy and leave the policymaker engagement to others.
Have organisations seek niches and moonshots to improve political framing and coalition building. As a corollary, don’t mind the gap: It’s fine if most AI safety organisations don’t have something to say on most AI-related issues.
Disambiguate the safety movement through costly and visible repositioning. It’s good if safety organisations sometimes disagree with legislation and framing advanced by ‘fellow’ safety advocates. A public-facing, controversial, political intra-movement debate is not something to be avoided for fear of providing ammunition that will be manufactured anyways. Hard nosedness can buy you credibility in important places.
Don’t approach all this as a matter of Machiavellian cleverness and pretense. I’m not saying the safety movement should act as if they did the above. This is rarely effective, and even more rarely believable. Doing this requires the genuine empowerment of new ideas and strategic directions.
Would the movement that followed these recommendations be a bit less of a unified front, a little bit less homogeneous? Certainly. But at this point, I am not 100% sure whether the depth of integration and strategic coordination has done the movement any particular service. It’s a gloomy time for AI safety policy, and minds may shift back on this – but for now, I would encourage serious changes in strategy.
What to Do About Funding?
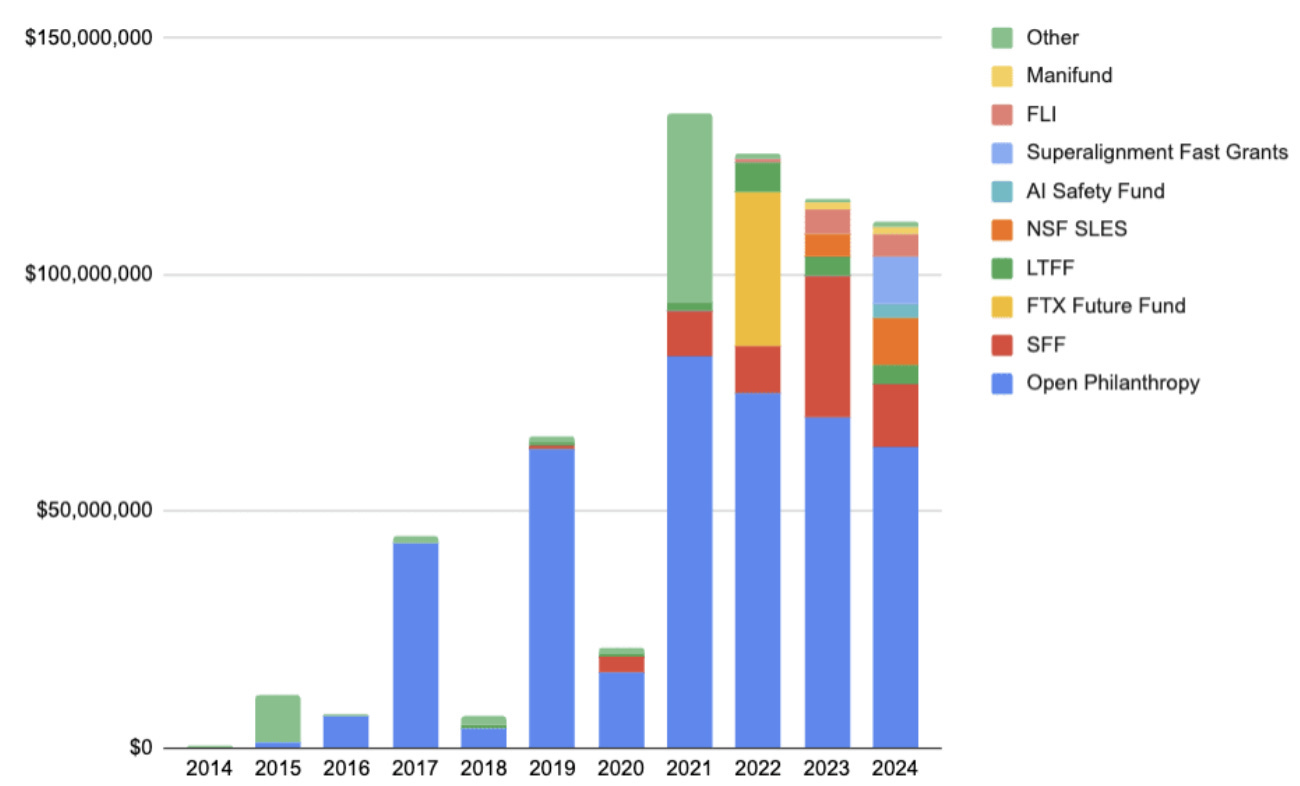
The elephant in the room behind these suggestions is funding diversification. A lot of commentary laments the outsized influence of a few active funding sources. I think it’s entirely possible that this influence contributes to a lot of the homogenisation trends I described. But you can’t just choose to diversify funding ex cathedra – it just happens that for many organisations, it’s getting funding from these few sources, or it’s not getting any. Diversification has, in fact, been a long-standing goal, but it hasn’t been too successful. I believe what I suggest could help with that: The funding system for an organisation that presents and networks as a safety organisation is narrow. But the funding system for partisan organisations, or organisations that plausibly present as being specifically about a more narrow policy area – security, labor, you name it – is much larger and more diverse. If safety organisations intersperse across the political spectrum, they also intersperse across funding sources, in a way that could counteract homogenizing forces and improve diversification. Present funders might just need to nudge the ecosystem along.
To wrap up, there’s one specific mistake the safety movement seems tempted to make and is worth flagging:
Don’t Reframe Without Reconsidering
The easiest trap to run into is reframing the movement without reconsidering the agenda. There’s been a growing consensus that ‘learning to speak Republican’ is advisable, and that maybe reframing AI safety, e.g. as AI security, could do the trick. But I think people aren’t that stupid. Pitching the very same policy agenda with a new coat of paint is not going to work. These issues are vetted at the very highest levels of scrutiny and sophistication – and AI policy will be at that level soon as it becomes more central to economic and foreign policy.

So if a newly-minted head of AI security for a major safety organisation goes to Congress and argues in favour of limitations on open-sourcing and cautions against loss of control, people will quickly realise he looks and sounds a lot like the previous head of AI safety, who had been a mainstay of the last years of AI policy. And at that point, that safety advocate needs a very good answer to ‘so what’s the difference between AI safety and AI security’. The answer cannot be ‘security sounds great to Republicans’. Sure, there are less and less questions like this as time passes, and once there’s been a Center for AI Security for some time, the reframing might take root. But ask any safety advocate, and they’ll tell you that ‘this will eventually work, but it’ll take time’. This answer is not remotely good enough.
Put a bit less facetiously: Reframing and renaming without a substantive shift in agenda will be futile at the levels of policy making targeted here. If and only if you do conduct a shift in agenda can renaming be an effective signifier of that shift. But the shift has to come first. And relative to the amount of conversations on how to signal a shift, I see very little discussion on what the actual shift should be. What 2023-era policy recommendations are safety advocates actually willing to give up? For instance, what about the worries around securitization and race dynamics – if those are still a prevalent part of the safety platform, it might be more of a stretch to call it compatible with a broader pivot to AI security.
Simply adding secure data centers and hawkish export controls to the existing platform has not been successful in removing the political baggage ‘AI safety’ has been saddled with, so tougher calls might have to be made. In reference to my aforementioned discussion: bipartisan appeal has to be bought, it can’t just be manifested. If AI safety wants to talk the Republican talk, it would have to walk the walk of making its platform much more palatable to the party’s politics as well.
What’s Next?
The AI safety movement is in a tough spot, and it will have to make some hard decisions to get out of it. None of the choices ahead are cheap, and it’ll take much more discussion to find out which ones are most prudent. Until then, I think the safety movement would be well-advised to diversify its portfolio of policy angles and political strategies.
 | A guest post by
|
Planning to reference this article in one of my AI Safety advocacy projects during my Fellowship with Successif. Thank you for your thoughtful work on this bulletin!
I’ve often observed a major disconnect between AI safety research and the more corporate-facing “Responsible AI” discourse. I primarily work in Spain and the UK, and in both contexts, I’ve noticed that local governments tend to consult nearby big tech companies (such as my own, or firms like Accenture and IBM) when developing AI policies or making decisions around AI deployment.
These companies often serve as informal policy advisors, but the individuals consulted typically come from the Responsible AI space rather than AI safety. While I’m starting to see early signs of convergence (e.g., some of us in industry are bringing safety principles into Responsible AI practices), this remains the exception rather than the norm.
The result is that local governments only receive a partial view of the risks and challenges involved. Many corporate stakeholders in Responsible AI aren’t familiar with foundational safety concepts like alignment (inner/outer), deceptive alignment, or mechanistic interpretability. Their focus tends to be on output-level auditing (fairness, bias, explainability) without engaging with the deeper issues surrounding the behavior of foundation models.
That’s why I think AI safety policy efforts should aim not only to educate policymakers, but also corporate stakeholders. In Europe especially, there’s a critical need for basic AI safety literacy at both levels. And if more people in influential corporate roles were aware of these safety concerns, they might be more willing to advocate for, and fund, relevant research. After all, big tech still holds a lot of the leverage when it comes to shaping what gets prioritised.